










.png)







.png)




















































HBM制作流程全梳理,高精度运动平台在其中承担了什么角色?
 2026-06-03
2026-06-03
分享:


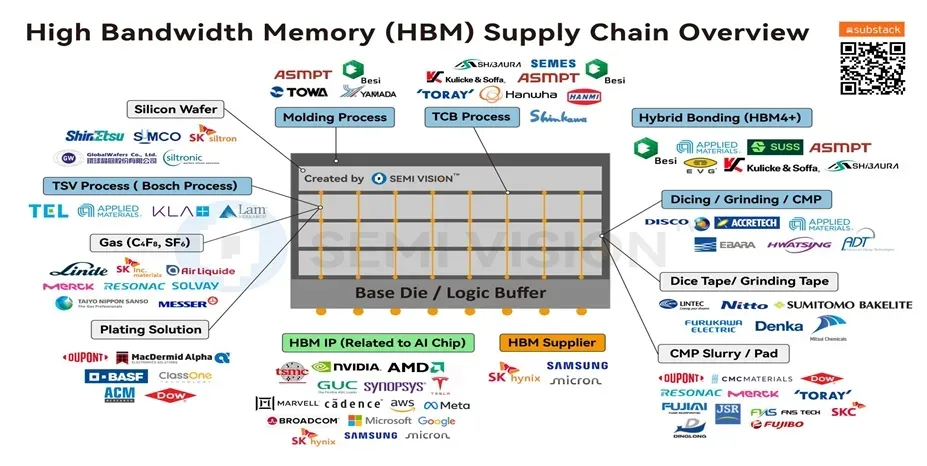
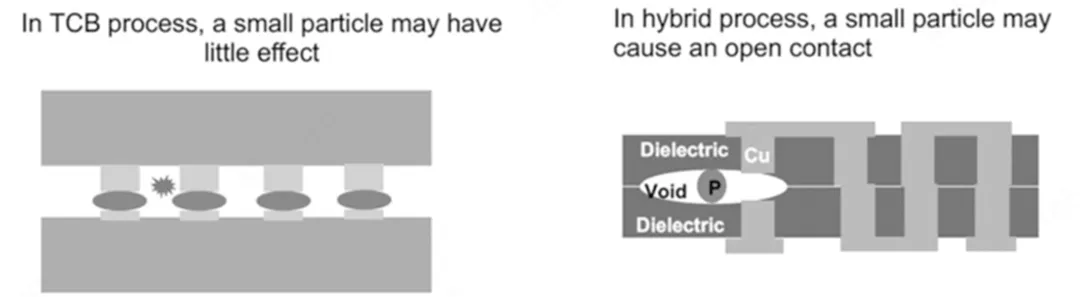
▲HBM全球供应链总览 图源自:锐芯闻 HBM(High Bandwidth Memory)是目前最高性能的 DRAM 内存解决方案,其核心技术为多层DRAM Die通过TSV(硅通孔)垂直堆叠在Logic Base Die上,再通过微凸块实现高密度互连。整个工艺属于先进3D集成范畴,工艺难度极高。 ▲AMD Radeon 390X Fury X显卡,GPU裸片环绕四颗SK海力士HBM高带宽内存模块 2015年,HBM首次商业应用于实际产品——AMD Radeon R9 Fury X 显卡,并采用了SK海力士的第一代HBM内存。 时至今日,SK海力士依然居于市占率首位。 SK海力士下一代12层HBM4样品已于2025年3月率先交付客户,并率先启动量产,同时完成了12层混合键合HBM的验证;三星正强力复苏,其HBM4的一大亮点是采用更先进的1c DRAM工艺,在博通测试中运行速度达11Gb/s;美光HBM4样品速率突破11Gb/s,带宽超过2.8TB/s,并在2026年第一季度率先实现为NVIDIA Vera Rubin平台的大规模量产出货。 HBM通常不是单独“制造一个处理器”,而是与GPU/AI加速器/CPU等逻辑芯片通过2.5D/3D先进封装集成,形成高带宽处理器系统。 在整个制造过程中,运动平台并非辅助工具,而是实现HBM向更高层数、更高带宽演进的基础使能技术,其精度水平直接决定了工艺边界与量产可行性。HBM代际越高,工艺越依赖运动控制能力。在光刻、贴装、键合、测试等工艺环节中,微米甚至纳米级误差都会显著影响HBM良率。 在凸点间距持续缩小、集成密度不断提高以及异构集成日趋复杂的趋势下,精密运动平台在HBM制作流程中具体承担了什么角色?又如何支撑下一代先进封装工艺的严苛需求? ·HBM关键制造流程· 01 前道工序-wafer制造 制造高性能DRAM颗粒和Logic Die(逻辑底座)的过程。 ■光刻:半导体设备精密运动的巅峰,也是前道工序中最重要的一环。投影式光刻仍是当前半导体制造领域的主流技术,这要求运动平台在高速运动中保持优异的在位稳定性,最小步进和重复定位精度。 ■刻蚀与离子注入:工件台须具备极高的重复定位精度,为高精度离子注入提供稳定的位置基准。 02 中道工序 - TSV与Bumping 这是HBM区别于普通DRAM的关键步骤,也是高精密运动平台需求爆发的环节。 ■TSV制造:需要在DRAM颗粒上钻出成千上万个深微孔,并填充铜导线。TSV孔径极小且垂直度要求极高,激光钻孔或深反应离子刻蚀(DRIE)都需要极其稳定的工件台。 ■Bumping制造:微凸点的尺寸(通常为5μm x 5μm)和间距(20μm)非常小,其位置精度直接影响后续的芯片堆叠质量,需要精密定位以确保数百万个Bump的一致性。 03 后道封装工序 - 堆叠与键合 这是HBM生产中最核心、难度最大的一个环节。 ■减薄:HBM需要垂直堆叠8层、12层甚至16层。一个12层HBM所需的芯片厚度约为50μm。而要达到16层,则需要将厚度减至30μm,因此必须将晶圆磨得极薄。在此过程中通常采用超低振动和高刚性气浮平台,防止极薄的晶圆在加工中碎裂或产生微裂纹。 ■切割 :减薄后需要将晶圆切割成独立的KGD,需要严格控制切割线精度。这个步骤需要高动态响应和定位精度的运动平台,保证裸片边缘完整性,防止崩边、裂纹等情况的出现。 ■芯片堆叠/键合: 将DRAM芯片层层精准堆叠后,通过热压键合或混合键合连接。混合键合作为一种无需焊料、无需金属凸点的先进封装技术,完美适配HBM向高密度、高带宽、低功耗升级的核心需求。 随着更多组件与互连被放入单一封装,潜在失效点的数量就会上升。任意一颗芯片或一个互连的缺陷,都可能造成高成本良率损失。在芯片-晶圆键合间距小于3μm的混合互连工艺中,通常要求键合对位精度(3σ)需控制在键合间距的10%以内(即间距<3μm 时,3σ 精度需<0.3μm)。 04 检测与最终成型 ■AOI光学检测:在HBM的量产线上,AOI凭借着快速全检的特性成为绝对主角。为了应对HBM复杂的三维堆叠结构,现在的AOI已经进化到了3D-AOI。主要检测Micro Bump是否有缺失、桥接;堆叠后的芯片是否有物理歪斜;晶圆表面是否有划痕或颗粒污染。 气浮式高速扫描平台可以确保在大面积快速扫描时平台振动极小,不干扰光学透镜成像。 HBM制造对精度的要求贯穿始终。尤其在多层堆叠键合环节,数万个微米级凸点需要亚微米甚至纳米级的贴装精度与多轴同步控制,是决定堆叠良率的核心因素。后续封装与检测同样依赖精密平台引导高速精准分选与缺陷识别。 在TSV光刻、超薄晶圆处理、多层堆叠键合及封装检测等关键节点,地心科技提供的不只是高精度平台系统,更可以以应用为导向进行深度定制,在确保亚微米乃至纳米级性能的同时,交付高可靠性与高价值密度的整体方案。